
Challenges in enterprise search
What are the challenges in enterprise search today, and why is it still so frustrating and difficult? According to McKinsey, a management consulting firm, employees spend 1.8 hours every day - 9.3 hours per week, on average – searching and gathering information. An IDC report says that employees spend 44% of their time on unsuccessful data activities.
AWS has identified two key challenges that employees, be it from small startups or large global enterprises, encounter: Low accuracy and complexity.
Low accuracy
Unstructured data accounts for 80% of the data in the enterprise today, and it’s growing exponentially every year. People search for information in unstructured data sources such as web pages, blogs, product documentation, policy documents, etc. But it’s always challenging to find required information by searching these types of data sources. The low accuracy problem mainly arises due to the mismatch between the search tools and the nature of the searching contents. Another reason for low accuracy is the keyword engines. Keyword engines are very prominent in the enterprise today, and as the name implies, they are ideal for keyword searches. The problem is that they are not enough to find precise answers in unstructured data. Therefore, when using keyword engines, users get lists of documents as search results, of which many are unrelated to the search query.
Complexity
Companies still have scattered data silos across their enterprises, and they have a vast amount of data stored in different formats. This data is spread across disjointed data sources from on-prem and in the cloud. As a result, it’s hard to set up all this information into a single search index, and once it creates an index, it requires extensive manual maintenance. For instance, tuning for relevance as the information in the enterprise changes. Overall, it’s a complex process to set up, maintain and aggregate all the data into a single search index.
Amazon Kendra
After further research and analysis, AWS initiated fixing the enterprise search problems for users by using machine learning technologies. As a result, AWS developed and launched Amazon Kendra, a highly accurate and easy-to-use intelligent search service powered by machine learning (ML). It intuitively searches the unstructured data using natural language search. Therefore, it’s capable of understanding the context of user queries and provides the better results.
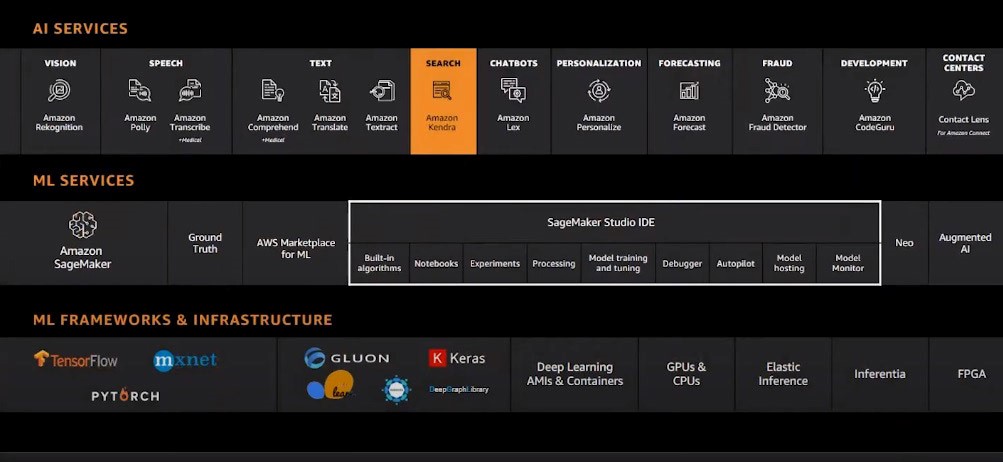
The AWS ML Stack
To understand the Amazon Kendra, first, it requires identifying the three layers of the AWS ML stack. The bottom layer is the frameworks and infrastructure layer, and this layer allows expert ML practitioners to build and maintain their ML platforms and underlying infrastructures. This layer consists of open-source software libraries such as TensorFlow, MXNet, and PyTorch. The middle layer is the ML service layer, and it allows ML developers and data scientists to build, train and deploy their ML models. This layer consists of services such as Amazon SageMaker and SageMaker Studio IDE. The top layer is the AI service layer, and it allows developers to use pre-trained and auto-trained models to add intelligence to any application without ML expertise. It’s this higher level of extraction where Amazon Kendra can be found. It allows users to add solution-oriented intelligence such as search into applications via API calls, and users don’t need to build and train their ML models using SageMaker.
How does Amazon Kendra help to find accurate information?
There are four components of Kendra that address the low accuracy problem, including Natural Language queries, NLU and Machine Learning core, Domain expertise, and Continuous Improvement. These components make it easy for users to find information. To deal with the complexity problem, Kendra has two core components include Native connectors and Simple API, and console experience code samples. These components make it simple and quick to set up.

Natural Language queries
Kendra’s ability to understand natural language queries and questions is really at the core of its search engine. It allows users to ask questions more precisely rather than typing numerous keywords in order to get the precise answers from the search engine.
NLU and Machine Learning core
To support Natural-Language Understanding, it requires building a new engine from the start with state-of-the-art Natural-Language Understanding. It helps understand the nuances of a language that are present in user queries and texts. In Kendra, there isn’t one single ML model that will always give the best answer, rather it consists of three different ML models that work in parallel to provide the best answers to the users:
Reading Comprehension: Reading comprehension will understand concepts in a text. It will extract key phrases, entities, language, syntax, and sentiments for analysis and extract an answer based on the semantic meaning of the query. It finds the exact phrase or exact paragraph that answers the user’s specific questions.
FAQ Matching: Kendra makes it easy for users to load up FAQ documents that have curated questions and answers. FAQ matching model will match the user query with the best matching question and provide the exact answer. In this case, users don’t have to search through the FAQ documents to find answers.
Document Ranking: For accurate document ranking, Kendra uses a deep learning semantic search model. It will return a list of relevant documents based on the meaning of the user query. It is similar to traditional search results where users get back a list of documents. But, Kendra’s context awareness of the relevancy of the return documents is significantly higher.
Domain expertise
In order for Kendra to understand user queries and texts better, AWS has pre-trained Kendra's models across several domains that can associate domain-specific terminology with user queries to return the best answer. Today, Kendra is optimized across 14 major domains.
Continuous Improvement
With continuous improvement, AWS makes sure that Kendra improves the accuracy over time and keeps up to date by observing search behavior and learning from user feedback. It allows retraining the models regularly and whenever the information in the enterprise changes. Soon, Kendra will be able to capture signals from click-throughs or user feedback and automatically retrain the models.
Use cases: Talk2020
Amazon Kendra is used to solve the enterprise search use cases. Wall Street Journal (WSJ) and Dow Jones took Kendra one step further and made it available to all their external customers and readers of the WSJ. In 2020, as the US presidential election was coming up, WSJ has launched Talk2020, a web-based intelligent search tool that uses Amazon Kendra and Factiva repository to make it easy and intuitive to search. It allowed users to ask questions and get answers about what the 2020 presidential candidates have said about any topic that was pertinent to the election.
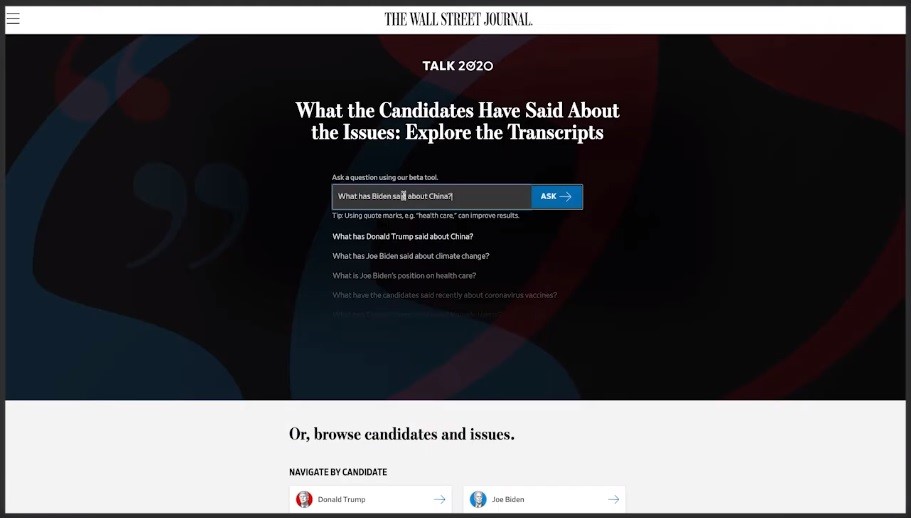
In Talk2020, users were able to ask questions. For instance, if a user asks, “What has Biden said about China?” then the application will return the most relevant quotes that Joe Biden has said about China. The results were filterable by date, keywords, or issues.
References and additional readings
AWS Events re:invent 2020:
https://www.youtube.com/playlist?list=PLhr1KZpdzukenb7A9aDtk3qHqMwy2Baxq
The WSJ case study:
https://aws.amazon.com/solutions/case-studies/the-wall-street-journal-case-study/
Amazon Kendra Home Page:
https://aws.amazon.com/kendra/
Amazon Kendra Blogs:
https://aws.amazon.com/blogs/machine-learning/category/artificial-intelligence/amazon-kendra/
Ebooks:
ML-Powered Search with Amazon Kendra
https://pages.awscloud.com/NAMER-devadopt-DL-Amazon-Kendra-eBook-7-Reasons-Why-2020-learn.html
Building a POC for Amazon Kendra
https://pages.awscloud.com/NAMER-devadopt-DL-Amazon-Kendra-eBook-How-to-build-a-POC-2020-learn.html
