
Difference between generative AI and traditional machine learning
Artificial intelligence is a broad term that describes systems capable of performing tasks that previously required human intelligence, such as reasoning, decision-making, and problem-solving. Machine learning, a subset of AI, involves using data to train models to identify patterns and make predictions based on new data. Deep learning, a specialized branch of machine learning, uses artificial neural networks inspired by the biological neural networks in the human brain. Deep learning enables handling complex problems that traditional machine learning techniques may struggle with, leading to significant advancements in fields such as computer vision, object detection, and natural language processing. Generative AI can be viewed as a subset of deep learning within the broader field of artificial intelligence. Unlike traditional machine learning models, which analyze and classify data for specific tasks, generative AI is powered by massive models that have been pre-trained on large datasets. Traditional machine learning models are narrow-focused, focusing on tasks like identifying fraudulent transactions, and often require separate models for different tasks. In contrast, generative AI uses a single foundation model capable of performing multiple tasks.
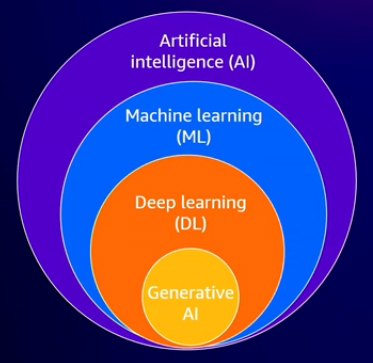
The evolution of machine learning and the emergence of generative AI
Generative AI has gained significant attention recently, and although its foundation is deep learning, the rapid growth in this field is a more recent phenomenon. This surge can be attributed to several key factors, including advancements in neural network architectures, the introduction of Generative Adversarial Networks (GANs), and the Transformer Architecture in 2017. Recent advances in neural network architectures, combined with access to vast amounts of publicly available internet-scale data such as text and images, have driven the growth of generative AI. Also, specialized computing resources, including GPU-backed instances and hardware accelerators, are crucial for running and training these large models and performing complex calculations. Significant investment in computational infrastructure and large research teams has also played a key role in this development.
What is generative AI?
Generative AI improves customer experiences, boosts employee productivity, and drives business value across various applications. Unlike traditional machine learning, which focuses on recognizing patterns, generative AI can create entirely new content, such as conversations, stories, images, and even code. The key characteristic is its generative nature, with models pre-trained on extensive datasets.
Common use cases for generative AI
Improve customer experience
According to Goldman Sachs' research, generative AI is projected to increase global GDP by over $7 trillion in the next decade. One notable application is in improving customer experiences through personalized chatbots. These virtual assistants can handle tasks like processing return requests, allowing customers to get help without waiting on hold. This improves the customer experience and significantly reduces the costs associated with traditional call centers and customer support operations. Importantly, this technology does not replace customer support agents but complements their roles. Generative AI can assist in initial triaging by integrating with backend systems to retrieve information about recent customer orders or past issues. Also, it can analyze and summarize years of call logs from customer support. By making sense of this raw textual data, generative AI can identify recurring customer problems and provide insights that help businesses focus on addressing these issues.
Boost employee productivity
Employees have numerous wikis, internal documents, and other information sources, but locating and accessing this information can be time-consuming and challenging. Advances in generative AI are enhancing intelligent search and question-answer capabilities, enabling quick access to relevant information for decision-makers and other team members. Also, generative AI can help in content creation beyond just text, such as generating images, audio, and visual content. Tools like Amazon CodeWhisperer enable code generation, significantly improving the developer experience.
Improve business operations
Generative AI can streamline and automate document processing at scale, replacing manual and tedious tasks. It can also assist with maintenance by analyzing IoT sensor data and standard operating procedures to help technicians diagnose issues more efficiently. Also, generative AI supports visual inspection and the creation of synthetic training data. This is particularly useful when training machine learning models, as high-quality training data is not always available at scale.
Creativity
From a creativity standpoint, significant advancements in generative AI are occurring across music, art, images, and animations. If content generation is part of your business, it's likely something you are already considering or should consider incorporating into your strategy.
Technical foundations and terminology
Understanding generative AI's technical foundations and terminology enhances one's understanding of how it operates and enables more effective communication with business and technical stakeholders involved in generative AI projects.
Foundation models
Foundation models are considered the core of many generative AI systems and are pre-trained on large datasets, often containing internet-scale data with billions of parameters. Unlike traditional machine learning models, which are typically designed for specific tasks and may require multiple models for different functions, the same foundation model can be adapted to a wide range of tasks. These tasks include content summarization, content generation, and applications across various modalities such as text, images, and code. Examples of foundation models include Amazon Titan, Stable Diffusion, Llama 2, and Claude, among others.
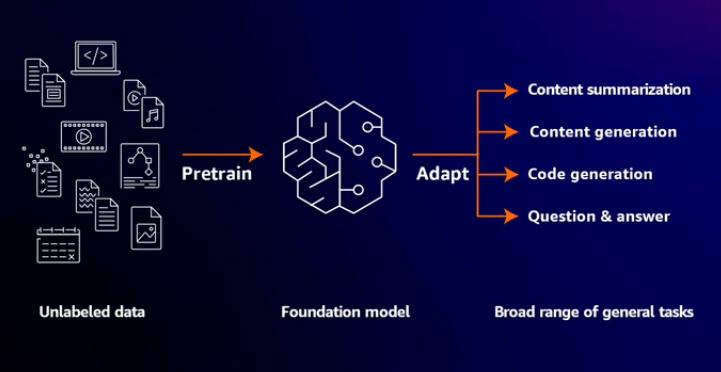
Pre-training
Foundation models are created through pre-training on vast amounts of data. To illustrate, imagine the task of learning everything on the internet. If you had to read 6 billion web pages at 60 seconds per page, it would take 6 billion minutes, an impractical endeavor. In contrast, a foundation model can accomplish this in a matter of months. Developing a foundation model from scratch currently costs millions of dollars. However, using pre-trained foundation models is faster and more cost-effective for organizations than training models from the ground up. Pre-training a foundation model requires processing massive amounts of unlabeled data, such as text, images, and audio, using large-scale training infrastructure with significant computing power. This process results in models with billions of parameters.
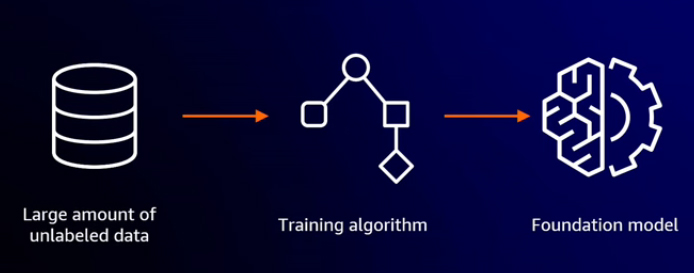
Transformer
Data processing in generative AI is managed by transformers, which can be considered the powerhouse of generative AI. Transformers are a specific type of architecture that acts like the system's brain, enabling the understanding and generation of complex patterns, languages, images, and other datasets. They are capable of focusing on multiple elements simultaneously. For example, consider the word "bank" in the sentences "I went to the bank last night to get some money" and "Now that ship is anchored on the bank." Despite the identical word, the meaning differs based on context. Transformers retain and use this contextual information, understanding the word itself and its context, meaning, and position within a larger string of text.
Tokenization and encoding
Let's use an example to show how transformer models work. Suppose you ask a generative AI model to complete the sentence, "puppy is to dog as kitten is to ____." Machine learning models work with numbers rather than text, involving extensive mathematical operations. It must be tokenized before passing the text to the model for processing. Tokenization breaks the text into smaller parts, such as words, phrases, individual characters, punctuation marks, etc. This standardization of input data makes it easier for the model to process. For example, in the input "puppy is to dog as kitten is to," the text is tokenized into manageable units for the model.

Word embedding
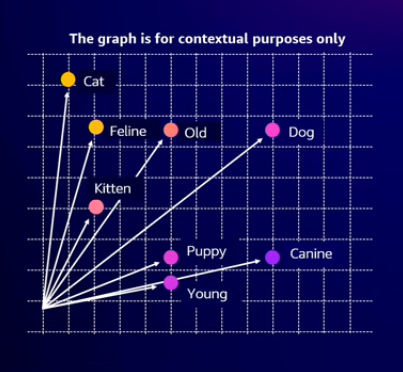
Generative AI embeddings are crucial for language understanding. They transform words that models don't directly process into meaningful vectors that machines can understand. A word embedding is an N-dimensional vector representing a word. For example, in a graphical representation, "Cat" and "Feline" are positioned close together, while "Canine," "Puppy," and "Young" are grouped differently. Word embeddings bridge human language and machine interpretation, enabling models to understand and respond to text.
Decoder
Once all tokens are encoded, the transformer's decoder uses these vector representations to predict the requested output or generate the next token. The transformer architecture includes mechanisms that allow it to focus on multiple elements simultaneously, examining different parts of the input to generate a matching output. Complex mathematical techniques are used to evaluate various options such as "cat," "bird," "bear," or "human" based on context. For example, in this scenario, the decoder would determine that "puppy is to dog as kitten is to cat" and then generate the word "cat" as the next token in the sentence. A key advantage of transformer models over their predecessors is their ability to parallelize computations. Unlike older models that process data sequentially, transformers handle all input tokens in parallel, enhancing processing efficiency.
Context
Context refers to the text within the active conversation. It does not persist, and it has a maximum size. Context is crucial for coherent interactions. For example, if you prompt the model with "What's the best place in Seattle to visit?" it responds with "The Columbia Center offers breathtaking views of the city skyline." Then you ask, "Will this be fun for children?" the transformer architecture must understand that "this" refers to the Columbia Center. The model maintains context within the same session, allowing it to follow the conversation without reestablishing previous interactions. This capability is useful in customer service scenarios. For example, if a customer calls about a specific order and the issue is resolved and then asks about something else, the context from the previous conversation is maintained. This means there is no need to reestablish or review prior details.
Reference:
AWS re:Invent 2023
