
A generative AI project can be divided into four key steps. First, defining the project's scope is important, especially for generative AI. Establishing a clear scope and prioritizing efforts are essential for success. This includes determining which aspects to focus on first and how to allocate time, funding, and resources. Then there's a variety of models available. Selecting an appropriate model based on the specific use case involves evaluating the features and performance of each model to determine the best fit. Training a foundational model from scratch is not necessary, as this can be costly, time-consuming, and require extensive computational resources. Instead, multiple open-source foundational models can be chosen and adapted for specific use cases. Next, the selected model can be adapted and further tailored using different techniques or relevant data. Then, use the model. Evaluating and addressing risk concerns and ethical considerations is important before deploying the model into production. Proper mitigation strategies must be in place to manage these issues. The intended usage of the model should be clearly defined, and integration into the application must be planned.
Step 1: Define the scope
Defining the scope may seem simple, but it is a crucial step for any project, particularly for generative AI initiatives. Key questions to consider include: Do customers want this? This could be external customers, internal customers, or employees. It is crucial to identify the target audience and desired outcomes, along with determining how success will be measured and what specific criteria will define it. Without addressing these factors at the project's start, it may be unclear how the new technology adds value to the business or meets expectations. Also, assess whether the organization can undertake the project by considering its difficulty, costs, funding, technical challenges, and required skill sets. Finally, determine whether to proceed by evaluating potential business value, revenue, return on investment, and competitor actions.
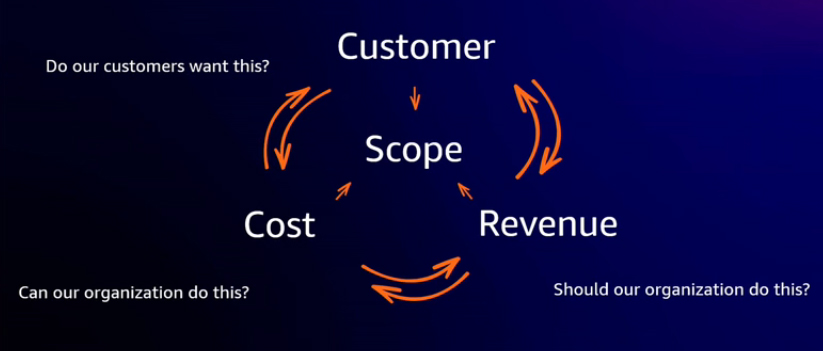
Not all use cases are created equal. It is important to assess different solutions' short-term and long-term impacts and their implementation timelines. Prioritizing efforts involves deciding whether to start multiple solutions in parallel or focus on specific ones. For example, Amazon CodeWhisperer can be used to enhance developer productivity with its generative AI-powered coding assistant. This requires minimal effort, such as providing training and encouragement to employees. In contrast, other use cases may require more extensive planning and a longer implementation time. For example, improving customer experience with a generative AI-powered chatbot or virtual assistant to reduce call center volume would likely involve more complex planning.
Step 2: Select a model
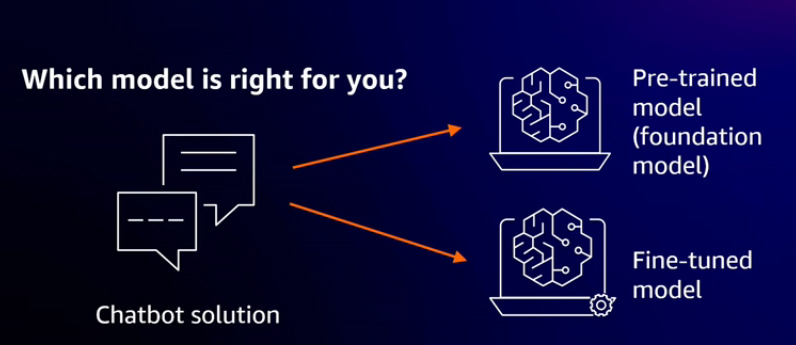
Once the scope is defined, the next step is selecting a model. Creating foundation models from scratch is a complex and costly effort, so choosing an existing model that suits your needs is often better. It is important to have a framework for evaluating which model and level of customization are suitable for your use case. For example, consider the AI-powered virtual assistant or chatbot example mentioned earlier. Determining whether customer inquiries will be general or more focused and domain-specific is important. Using a pre-trained foundation model out of the box may be sufficient for general tasks. However, a more specialized model may be necessary for use cases requiring domain-specific responses tailored to particular customers and products.
Fine-tuning an existing pre-trained foundation model allows customization and tailoring to specific needs. This approach is useful when dealing with complex datasets or addressing complex question-and-answer scenarios within domain-specific data and knowledge. Fine-tuning an existing model requires additional computational resources, though not as extensive as those needed for creating a foundational model from scratch. Fine-tuning involves tailoring and customizing the model to meet domain-specific needs.
Step 3: Adapt the model
Several methods exist for customizing and tailoring model outputs based on specific needs and use cases. Two popular methods are prompt engineering and fine-tuning.
Prompt engineering involves defining and refining the prompts or inputs given to the model to produce outputs that better align with your needs. For example, if you have meeting notes and need to summarize them into meeting minutes, you could simply provide the notes and request a summary. However, if standardization is important for your business or customer expectations, prompt engineering can help. By providing several examples in the input, you can guide the model to produce outputs that meet specific standards without fine-tuning the model itself. This approach adjusts the input or prompts to better align with the desired output.
Fine-tuning can be seen as an extension of the pre-training process that creates a foundational model. It involves adjusting a pre-existing model to create a new, specialized version tailored to specific needs. This process requires substantial computational resources, high-quality labeled data, and at least 500 examples. For example, suppose you have call center logs and need standardized, structured outputs detailing issues and resolutions. In that case, fine-tuning can adapt the model using a few thousand high-quality, labeled examples. During fine-tuning, some parameters are adjusted to better fit the use case. The cost of fine-tuning can escalate quickly, especially with larger models. Models vary in size and complexity, ranging from 10 billion to 100 billion parameters. The choice of model will depend on the complexity required for your use case and can significantly impact the overall cost.
Step 4: Use the model
Deploying a model is not as simple as clicking a button and releasing it to production. A broad plan is required, which should have been established during the initial scope definition phase. This plan should detail the intended usage, target audience, success criteria, and methods for measuring effectiveness.
Responsible AI considerations must also be addressed, and a strategy for ongoing monitoring should be implemented. Monitoring is important not only to ensure the solution is functioning as expected but also to collect data that can be used for feedback. Using a larger dataset collected over time, this feedback can inform future adjustments and fine-tuning.
Many of the same MLOps principles applied to traditional machine learning models also apply to generative AI models. Best practices for MLOps, often referred to as FMOps, ensure that models are not only deployed but also remain aligned with business goals. It's important to have a plan for collecting feedback from users. Techniques such as reinforcement learning with human feedback (RLHF) play a significant role here. For example, presenting users with two different outputs and asking them to select their preferences can provide valuable data to improve the model over time. Also, tracking changes to the pre-trained model is important for retraining or fine-tuning using RLHF or other methods. This continuous feedback loop helps in enhancing the model's performance.
Generative AI Considerations
While generative AI offers significant benefits, it is important to recognize and address potential risks and challenges. First, determine whether generative AI is appropriate for the specific problem or task. It may not always be the right solution. If it is, consider the associated risks and whether they can be mitigated. Key considerations include fairness and privacy.
Fairness
Ensuring fairness involves avoiding unintended consequences for specific groups, which is especially critical in highly regulated industries such as lending and loan approval. This is more challenging with generative AI than with traditional machine learning models. For example, in a traditional ML model for predicting credit card fraud or loan approvals, the training dataset can be carefully curated to include diverse demographic examples, reducing the risk of bias. However, with generative AI models, this becomes more complex. Fairness is more difficult to define, measure, and enforce, making it a critical concern that should be prioritized when implementing generative AI solutions.
Privacy
Privacy is a significant concern with generative AI, as it is important to ensure that these models do not leak sensitive or proprietary information, including customer data, that was part of their training dataset. It is essential that any data used to fine-tune foundation models remains secure and is not shared with third-party model providers or used to enhance the base models.
Generative AI Risks and Mitigation
With the significant power of generative AI comes the responsibility to use it wisely. As this technology evolves rapidly, it is important to remain aware of the associated risks and practice responsible AI. Let's explore some risks and the mitigation strategies that can be employed to address these challenges.
Toxicity
Toxicity refers to harmful, inflammatory, or offensive content that a generative AI model might produce. One approach to mitigate this risk is carefully curating the training data to exclude such examples. Another strategy is implementing guardrail models that detect and filter out unwanted content before it reaches the end user.
Hallucinations
Another risk is hallucinations, where generative AI models produce assertions or claims that are not factually correct. To address this, educating users to verify and validate the information generated by these models is important. Users should be aware of this risk and take steps to check outputs for accuracy.
Intellectual property
Intellectual property concerns about privacy, ensuring that data is secured through encryption and filtering. Generated content can be filtered to identify and remove any protected material. If such content is detected, it should be promptly removed.
Plagiarism and cheating
Due to generative AI, plagiarism and cheating are becoming more common in educational settings. However, this technology also offers significant benefits, such as personalized learning assistance. It's important to balance these risks and benefits properly.
Disruption of the nature of work
Generative AI will disrupt the nature of work, not necessarily by eliminating jobs but by altering how tasks are performed. It is also likely to create entirely new job roles that are not yet defined. It is important to be aware of these changes and communicate with employees about them.
Reference:
AWS re:Invent 2023
