Foundation Models and Large Language Models
How does a foundation model function?
Before foundational models, machine learning was the primary approach. In machine learning, you develop a model and define its specific use case. Based on the problem at hand, you choose between supervised, semi-supervised, or unsupervised learning. In contrast, foundational models use deep neural networks designed to emulate human brain functionality, enabling them to handle complex tasks. For example, these models can generate text, create images, or power chatbot applications. They are pre-trained on large, unlabeled datasets, allowing them to perform a wide range of general tasks such as text summarization, image creation, or answering questions.
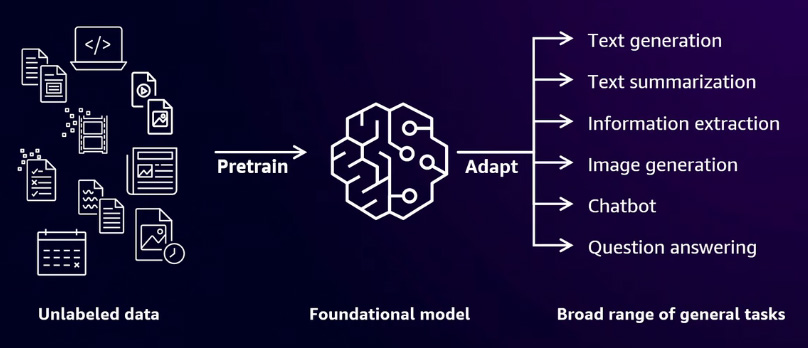
Training foundation models
When working with a foundational model, the process involves multiple stages to achieve optimal results.
Pretrain
The first step is pre-training. During pre-training, the model uses self-supervised learning to process an extensive dataset, often consisting of trillions of words. This stage leverages a deep neural network to capture the context within the text. For example, when you ask the model a question or request a summary of an email or text, it relies on the knowledge acquired during pre-training. In this phase, if the model encounters a word like "drink," it determines whether the word is used as a noun or a verb by analyzing the context provided by the massive dataset.
Fine-tuning
You begin with an existing pre-trained foundational model and then fine-tune it using your own dataset. This process is particularly useful when you have a specific use case in mind. For example, if you need to generate reports for medical research, you can fine-tune the foundational model using data from medical journals.
Prompt engineering
You optimize the prompts used when interacting with the foundational model, whether asking a question or generating an image. This process, known as prompt engineering, doesn't require retraining the model. Instead, you refine the input to guide the foundational model in generating the desired output.
Types of foundational models
There are two main types of foundational models. The first type is text-to-text, commonly known as a large language model (LLM), which is a subset of foundational models. These models are used for language-based tasks such as building chatbot applications, summarizing text, or answering questions.
The next type is text-to-image. In this case, the model takes natural language input, your text prompt, and generates an image based on that input. A well-known example of a text-to-image foundational model is Stable Diffusion, which can create images from descriptive text prompts.
Large language models
Large language models are a subset of foundational models. They accept text as input and generate text as output. This makes them well-suited for tasks like summarizing emails, news articles, or other types of written content. Large language models are built on transformer architecture, which enables them to process and generate text efficiently. When you input text into a large language model, the text is first converted into numerical representations, as computers process numbers more effectively than raw text. Within the transformer architecture, the model analyzes these numerical representations and identifies relationships between words based on patterns in the dataset. For example, if you input the word "cat," the model converts it into a number and searches for similar numerical representations, such as those associated with "feline." Once the model determines the most relevant words, it generates an output by converting the numerical values back into text using a decoder.
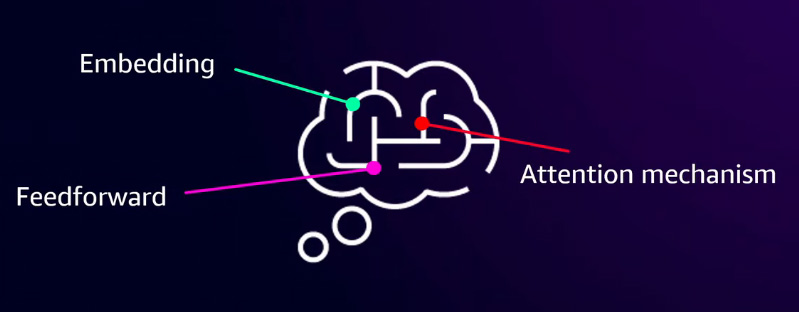
Neural networks
In a foundational model, a neural network is used to process and understand words or content through several key components. The embedding layer serves as the input layer, converting text into numerical representations that the model can process. Next, the feedforward layer assigns numerical weights to words, helping the model identify similarities and relationships between them. Finally, the attention mechanism enables the model to focus on relevant parts of the input text, analyzing context to ensure a deeper understanding of meaning. Together, these components allow the foundational model to interpret and generate meaningful responses based on the provided input.
LLM use cases
Large language models offer a wide range of applications across various domains.
- One key use case is chatbots. Businesses can integrate LLMs into customer support systems, allowing customers to ask product-related questions and receive instant, accurate responses.
- LLMs can also boost employee productivity, especially for developers. Instead of manually searching through documentation, developers can leverage LLMs to generate code snippets, accelerating the development process.
- Another application is enhancing creativity. LLMs can assist in generating marketing materials, such as product descriptions or campaign visuals, using text-to-image models. This capability helps businesses streamline content creation.
- LLMs can accelerate process optimization by automating tasks such as meeting summaries and report generation. After a meeting, an LLM can quickly generate a structured summary or document, reducing manual effort.
Key Concepts in Prompt Engineering
In prompt engineering, it's important to understand the difference between fine-tuning and prompt-tuning.
Fine-tuning
Fine-tuning involves taking an existing foundational or large language model and retraining it using your own dataset. For example, if you need to generate medical health reports, you might fine-tune the model with data from healthcare journals. This process requires additional computational resources and time.
Prompt-tuning
Prompt-tuning, on the other hand, does not require modifying or retraining the model. Instead, you provide a set of instructions or a well-crafted prompt when interacting with the model. This method allows you to influence the output without retraining, making it a more resource-efficient approach.
Elements of a prompt
Prompt engineering involves several key elements that shape the model's response:
Instructions: Define what you want the model to do, whether it's generating text, creating an image, or answering a question. Well-structured instructions improve response accuracy.
Context: Providing background information helps refine the model's output. For example, if generating a report or an email, including relevant context ensures that the content aligns with the intended purpose.
Input Data: Adding specific details or reference data can influence the output, making responses more relevant and tailored to your needs.
Output Indicator: Defining the desired format or style of the output ensures clarity. For example, if generating an image, specifying the file format (e.g., PNG or JPEG) helps the model produce the expected result.

Best practices for designing effective prompts
To create effective prompts, follow these key principles:
Be clear and concise: Use straightforward language to ensure the model understands your request. Ambiguous or overly complex prompts may lead to less accurate responses.
Include context: If writing an essay or producing a specific type of content, provide relevant background information to improve output quality.
Use directives: Specify instructions such as "Summarize this text in two sentences" or "Write a 500-word article." Clear directives help guide the model toward the desired result.
Define the output format: Indicate the expected format, whether it's a structured summary, a specific text length, or a particular image format like PNG or JPEG.
Start with a question: Framing prompts with what, who, how, or when helps refine the request and ensures more precise responses.
Provide example responses: To guide the model, include sample inputs and expected outputs. For example, when performing sentiment analysis, provide labelled examples of positive, neutral, and negative sentiments.
Break up complex tasks: Instead of asking multiple questions in a single prompt, break them into more minor, focused queries for better accuracy.
Experiment and be creative: Test different foundational models and compare results to find the best approach for your specific use case.
Basic Prompt Techniques
Zero-shot prompting
With zero-shot prompting, you provide only the question without any additional context or examples. The model relies on its pre-trained knowledge to generate a response. For example, if you want to analyze the sentiment of a paragraph using a zero-shot approach, you simply ask the question without specifying the expected output. Despite the minimal input, the foundational model or large language model can still understand your inquiry and generate the appropriate response.

Few-shot prompting
With few-shot prompting, you provide examples or output samples within your prompt to guide the model's response. For example, suppose you want to determine whether a paragraph expresses a positive, negative, or neutral sentiment. In that case, you include a few labelled examples of similar text and their corresponding sentiment classifications. By doing so, the model gains context and a clearer understanding of the expected output.

Chain-of-thought prompting
With chain-of-thought prompting, complex questions are broken down into smaller, sequential steps. Instead of asking a single long question, you structure the prompt into a series of smaller, logical sub-questions, guiding the model to reason step by step. This approach improves accuracy and helps the model generate more structured and coherent responses.

You can combine chain-of-thought and few-shot prompting to enhance the model's reasoning ability. In this approach, you provide multiple example questions, each with step-by-step reasoning processes and their final answers.
Reference:
AWS Events
